DP-203: Data Engineering on Microsoft Azure
Question 51
You have an Azure data factory that has two pipelines named PipelineA and PipelineB.
PipelineA has four activities as shown in the following exhibit.

PipelineB has two activities as shown in the following exhibit.

You create an alert for the data factory that uses Failed pipeline runs metrics for both pipelines and all failure types. The metric has the following settings:
- Operator: Greater than
- Aggregation type: Total
- Threshold value: 2
- Aggregation granularity (Period): 5 minutes
- Frequency of evaluation: Every 5 minutes
Data Factory monitoring records the failures shown in the following table.
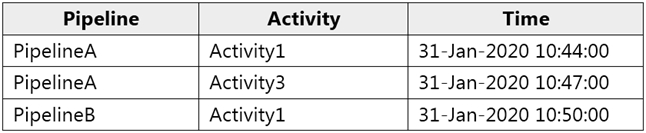
For each of the following statements, select yes if the statement is true. Otherwise, select no.

No - No - No
No - No - Yes
No - Yes - No
No - Yes - Yes
Yes - No - No
Yes - No - Yes
Yes - Yes - No
Yes - Yes - Yes
Answer is No - No - Yes
Box 1: No
Only one failure at this point.
Box 2: No
Only two failures within 5 minutes.
Box 3: Yes
More than two (three) failures in 5 minutes
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/alerts-insights-configure-portal
You plan to monitor an Azure data factory by using the Monitor & Manage app.
You need to identify the status and duration of activities that reference a table in a source database.
Which three actions should you perform in sequence?
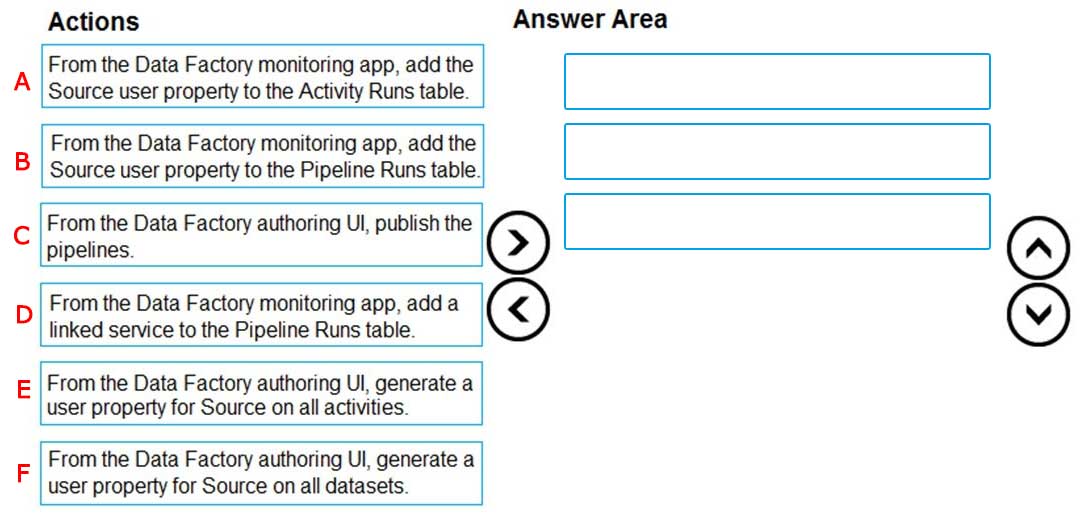
A-B-C
B-A-D
C-B-E
D-A-B
E-B-C
F-A-D
A-E-B
B-D-F
Answer is E-B-C
Step 1: From the Data Factory authoring UI, generate a user property for Source on all activities.
Step 2: From the Data Factory monitoring app, add the Source user property to Activity Runs table.
You can promote any pipeline activity property as a user property so that it becomes an entity that you can monitor. For example, you can promote the Source and
Destination properties of the copy activity in your pipeline as user properties. You can also select Auto Generate to generate the Source and Destination user properties for a copy activity.
Step 3: From the Data Factory authoring UI, publish the pipelines
Publish output data to data stores such as Azure SQL Data Warehouse for business intelligence (BI) applications to consume.
References:
https://docs.microsoft.com/en-us/azure/data-factory/monitor-visually
You have an Azure Data Factory that contains 10 pipelines.
You need to label each pipeline with its main purpose of either ingest, transform, or load. The labels must be available for grouping and filtering when using the monitoring experience in Data Factory.
What should you add to each pipeline?
a resource tag
a user property
an annotation
a run group ID
a correlation ID
Answer is an annotation
Annotations are additional, informative tags that you can add to specific factory resources: pipelines, datasets, linked services, and triggers. By adding annotations, you can easily filter and search for specific factory resources.
Reference:
https://www.cathrinewilhelmsen.net/annotations-user-properties-azure-data-factory/
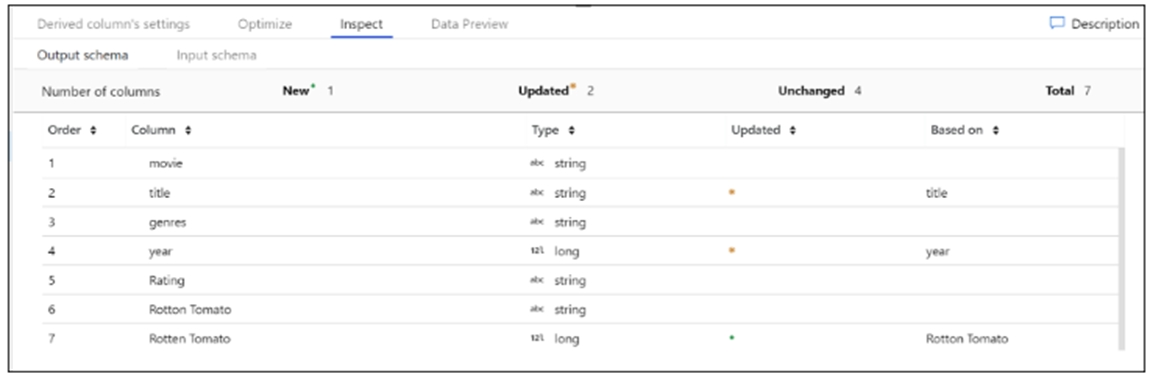
You are implementing mapping data flows in Azure Data Factory to convert daily logs of taxi records into aggregated datasets. You configure a data flow and receive the error shown in the following exhibit.
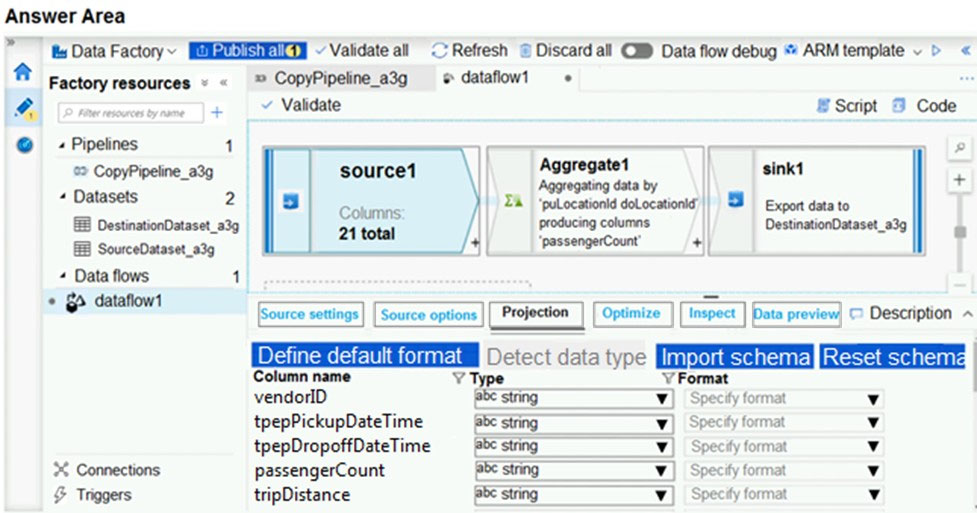
Check the answer section
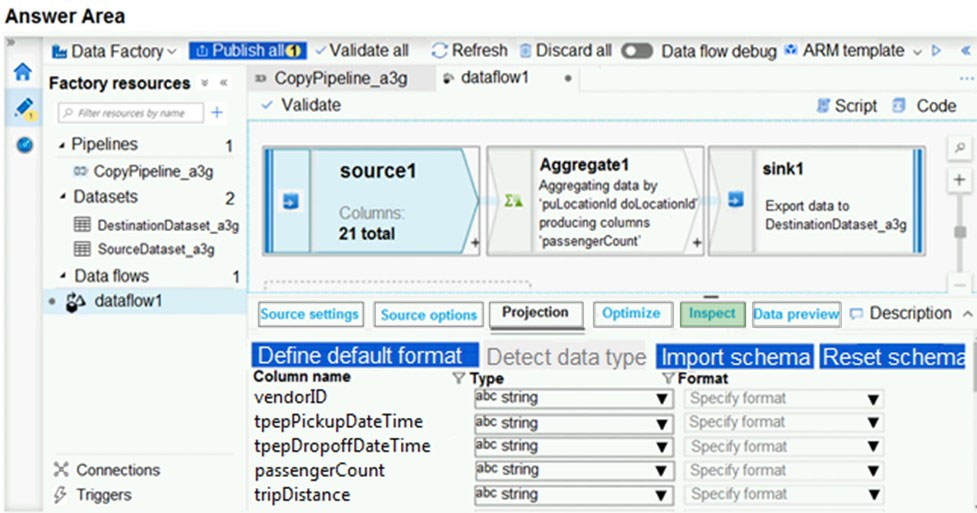 The Inspect tab provides a view into the metadata of the data stream that you're transforming. You can see column counts, the columns changed, the columns added, data types, the column order, and column references. Inspect is a read-only view of your metadata. You don't need to have debug mode enabled to see metadata in the Inspect pane.
The Inspect tab provides a view into the metadata of the data stream that you're transforming. You can see column counts, the columns changed, the columns added, data types, the column order, and column references. Inspect is a read-only view of your metadata. You don't need to have debug mode enabled to see metadata in the Inspect pane.
 Reference:
https://docs.microsoft.com/en-us/azure/data-factory/concepts-data-flow-overview
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/concepts-data-flow-overview
You have an Azure subscription that contains an Azure Storage account.
You plan to implement changes to a data storage solution to meet regulatory and compliance standards.
Every day, Azure needs to identify and delete blobs that were NOT modified during the last 100 days.
Solution: You schedule an Azure Data Factory pipeline with a delete activity.
Yes
No
Answer is Yes
You can use the Delete Activity in Azure Data Factory to delete files or folders from on-premises storage stores or cloud storage stores.
Azure Blob storage is supported.
Note: You can also apply an Azure Blob storage lifecycle policy.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/delete-activity
https://docs.microsoft.com/en-us/azure/storage/blobs/storage-lifecycle-management-concepts?tabs=azure-portal
You are creating dimensions for a data warehouse in an Azure Synapse Analytics dedicated SQL pool.
You create a table by using the Transact-SQL statement shown in the following exhibit.

Use the drop-down menus to select the answer choice that completes each statement based on the information presented in the graphic.
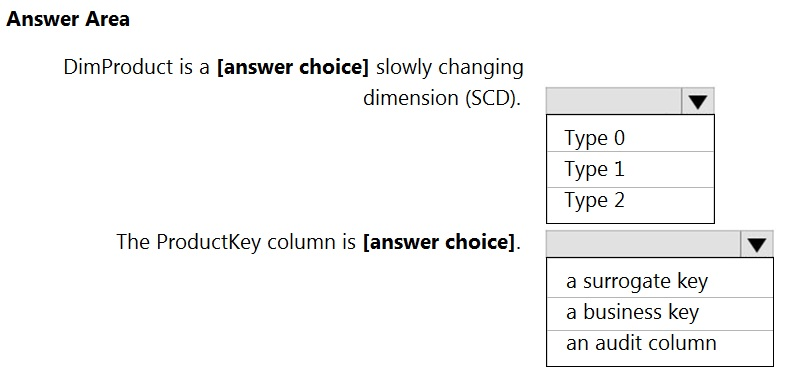
Answer is Type 1 and surrogate key
"In data warehousing, IDENTITY functionality is particularly important as it makes easier the creation of surrogate keys."
Why ProductKey is certainly not a business key: "The IDENTITY value in Synapse is not guaranteed to be unique if the user explicitly inserts a duplicate value with 'SET IDENTITY_INSERT ON' or reseeds IDENTITY". Business key is an index which identifies uniqueness of a row and here Microsoft says that identity doesn't guarantee uniqueness.
References:
https://azure.microsoft.com/en-us/blog/identity-now-available-with-azure-sql-data-warehouse/
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-identity
https://docs.microsoft.com/en-us/learn/modules/populate-slowly-changing-dimensions-azure-synapse-analytics-pipelines/3-choose-between-dimension-types
You have files and folders in Azure Data Lake Storage Gen2 for an Azure Synapse workspace as shown in the following exhibit.
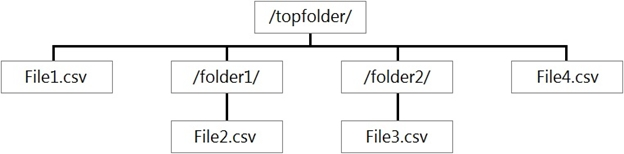
You create an external table named ExtTable that has LOCATION='/topfolder/'.
When you query ExtTable by using an Azure Synapse Analytics serverless SQL pool, which files are returned?
File2.csv and File3.csv only
File1.csv and File4.csv only
File1.csv, File2.csv, File3.csv, and File4.csv
File1.csv only
Answer is File1.csv and File4.csv only
Unlike Hadoop external tables, native external tables don't return subfolders unless you specify /** at the end of path. In this example, if LOCATION='/webdata/', a serverless SQL pool query, will return rows from mydata.txt. It won't return mydata2.txt and mydata3.txt because they're located in a subfolder. Hadoop tables will return all files within any sub-folder.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql/develop-tables-external-tables?tabs=hadoop
You need to output files from Azure Data Factory.
Which file format should you use for each type of output?

Box 1: Parquet
Parquet stores data in columns, while Avro stores data in a row-based format. By their very nature, column-oriented data stores are optimized for read-heavy analytical workloads, while row-based databases are best for write-heavy transactional workloads.
Box 2: Avro
An Avro schema is created using JSON format.
AVRO supports timestamps.
Note: Azure Data Factory supports the following file formats (not GZip or TXT).
- Avro format
- Binary format
- Delimited text format
- Excel format
- JSON format
- ORC format
- Parquet format
- XML format
Reference:
https://www.datanami.com/2018/05/16/big-data-file-formats-demystified
You use Azure Data Factory to prepare data to be queried by Azure Synapse Analytics serverless SQL pools.
Files are initially ingested into an Azure Data Lake Storage Gen2 account as 10 small JSON files. Each file contains the same data attributes and data from a subsidiary of your company.
You need to move the files to a different folder and transform the data to meet the following requirements:
- Provide the fastest possible query times.
- Automatically infer the schema from the underlying files.
How should you configure the Data Factory copy activity?

1) Merge Files - Question clearly says "initially ingested as 10 small json files". There is no hint on hierarchy or partition information. so clearly we need to merge these files for better performance
2) Parquet -> Always gives better performance for columnar based data
Reference:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-performance-tuning-guidance
You are creating an Azure Data Factory data flow that will ingest data from a CSV file, cast columns to specified types of data, and insert the data into a table in an Azure Synapse Analytic dedicated SQL pool. The CSV file contains three columns named username, comment, and date.
The data flow already contains the following:
- A source transformation.
- A Derived Column transformation to set the appropriate types of data.
- A sink transformation to land the data in the pool.
You need to ensure that the data flow meets the following requirements:
- All valid rows must be written to the destination table.
- Truncation errors in the comment column must be avoided proactively.
- Any rows containing comment values that will cause truncation errors upon insert must be written to a file in blob storage.
Which two actions should you perform?
To the data flow, add a sink transformation to write the rows to a file in blob storage.
To the data flow, add a Conditional Split transformation to separate the rows that will cause truncation errors.
To the data flow, add a filter transformation to filter out rows that will cause truncation errors.
Add a select transformation to select only the rows that will cause truncation errors.
Answer is A and B
B: Example:
1. This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five will go into the GoodRows stream.
Any row that is larger than five will go into the BadRows stream.
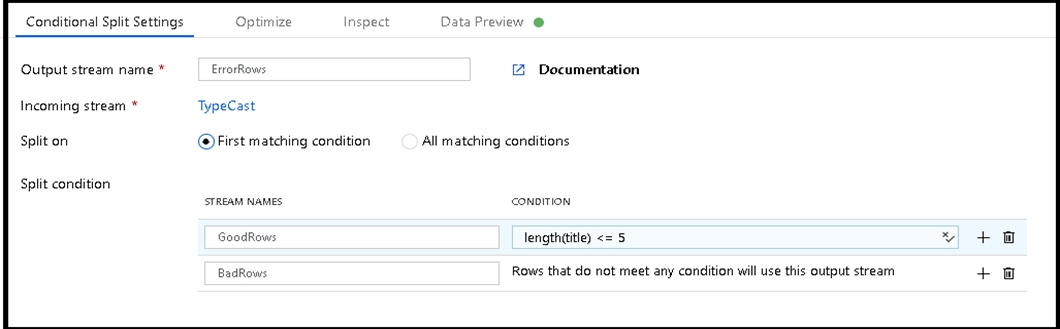
2. This conditional split transformation defines the maximum length of "title" to be five. Any row that is less than or equal to five will go into the GoodRows stream.
Any row that is larger than five will go into the BadRows stream.
A:
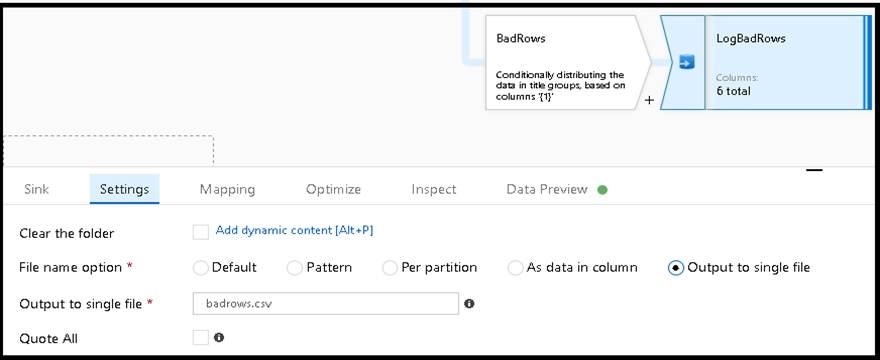
3. Now we need to log the rows that failed. Add a sink transformation to the BadRows stream for logging. Here, we'll "auto-map" all of the fields so that we have logging of the complete transaction record. This is a text-delimited CSV file output to a single file in Blob Storage. We'll call the log file "badrows.csv".
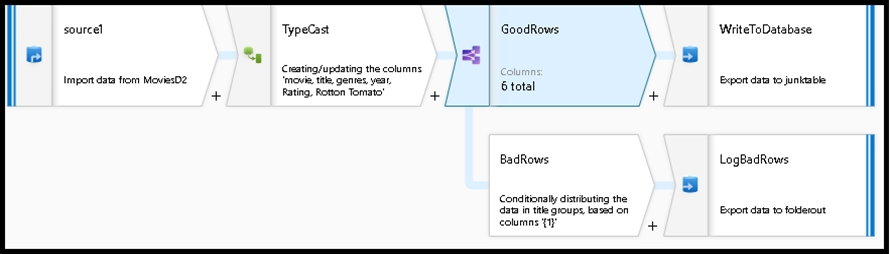
4. The completed data flow is shown below. We are now able to split off error rows to avoid the SQL truncation errors and put those entries into a log file.
Meanwhile, successful rows can continue to write to our target database.
Reference:
https://docs.microsoft.com/en-us/azure/data-factory/how-to-data-flow-error-rows