DP-203: Data Engineering on Microsoft Azure
Question 141
You manage an enterprise data warehouse in Azure Synapse Analytics.
Users report slow performance when they run commonly used queries. Users do not report performance changes for infrequently used queries.
You need to monitor resource utilization to determine the source of the performance issues.
Which metric should you monitor?
DWU percentage
Cache hit percentage
DWU limit
Data IO percentage
Answer is Cache hit percentage
Monitor and troubleshoot slow query performance by determining whether your workload is optimally leveraging the adaptive cache for dedicated SQL pools.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-how-to-monitor-cache
You configure monitoring from an Azure Synapse Analytics implementation. The implementation uses PolyBase to load data from comma-separated value (CSV) files stored in Azure Data Lake Storage Gen2 using an external table.
Files with an invalid schema cause errors to occur.
You need to monitor for an invalid schema error.
For which error should you monitor?
EXTERNAL TABLE access failed due to internal error: 'Java exception raised on call to HdfsBridge_Connect: Error [com.microsoft.polybase.client.KerberosSecureLogin] occurred while accessing external file.'
Cannot execute the query
EXTERNAL TABLE access failed due to internal error: 'Java exception raised on call to HdfsBridge_Connect: Error [Unable to instantiate LoginClass] occurred while accessing external file.'
EXTERNAL TABLE access failed due to internal error: 'Java exception raised on call to HdfsBridge_Connect: Error [No FileSystem for scheme: wasbs] occurred while accessing external file.'
Answer is Cannot execute the query
Error message: Cannot execute the query "Remote Query"
Possible Reason:
The reason this error happens is because each file has different schema. The PolyBase external table DDL when pointed to a directory recursively reads all the files in that directory. When a column or data type mismatch happens, this error could be seen in SSMS.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/polybase/polybase-errors-and-possible-solutions
You have an Azure Synapse Analytics dedicated SQL pool.
You run PDW_SHOWSPACEUSED('dbo.FactInternetSales'); and get the results shown in the following table.
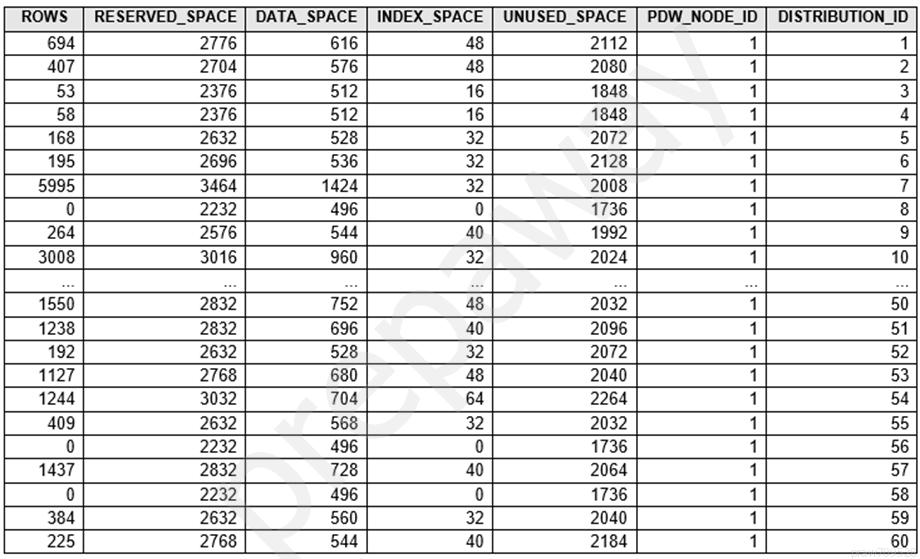
Which statement accurately describes the dbo.FactInternetSales table?
All distributions data.
The table contains less than 10,000 rows.
The table uses round-robin distribution.
The table is skewed.
Answer is The table is skewed.
Data skew means the data is not distributed evenly across the distributions.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
You have an enterprise data warehouse in Azure Synapse Analytics named DW1 on a server named Server1.
You need to determine the size of the transaction log file for each distribution of DW1.
What should you do?
On DW1, execute a query against the sys.database_files dynamic management view.
From Azure Monitor in the Azure portal, execute a query against the logs of DW1.
Execute a query against the logs of DW1 by using the Get-AzOperationalInsightsSearchResult PowerShell cmdlet.
On the master database, execute a query against the sys.dm_pdw_nodes_os_performance_counters dynamic management view.
Answer is On DW1, execute a query against the sys.database_files dynamic management view.
For information about the current log file size, its maximum size, and the autogrow option for the file, you can also use the size, max_size, and growth columns for that log file in sys.database_files.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/logs/manage-the-size-of-the-transaction-log-file
You are designing an enterprise data warehouse in Azure Synapse Analytics that will store website traffic analytics in a star schema. You plan to have a fact table for website visits. The table will be approximately 5 GB.
You need to recommend which distribution type and index type to use for the table. The solution must provide the fastest query performance.
What should you recommend?
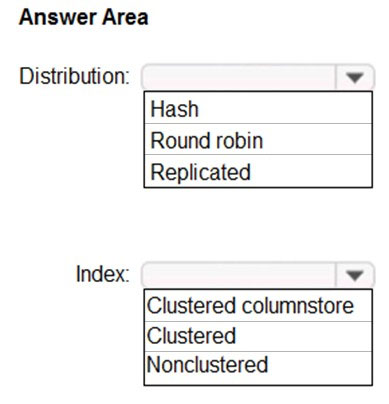
Box 1: Hash
Consider using a hash-distributed table when:
The table size on disk is more than 2 GB.
The table has frequent insert, update, and delete operations.
Box 2: Clustered columnstore
Clustered columnstore tables offer both the highest level of data compression and the best overall query performance.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-index
You have an Azure Synapse Analytics job that uses Scala.
You need to view the status of the job.
What should you do?
From Synapse Studio, select the workspace. From Monitor, select SQL requests.
From Azure Monitor, run a Kusto query against the AzureDiagnostics table.
From Synapse Studio, select the workspace. From Monitor, select Apache Sparks applications.
From Azure Monitor, run a Kusto query against the SparkLoggingEvent_CL table.
Answer is From Synapse Studio, select the workspace. From Monitor, select Apache Sparks applications.
Use Synapse Studio to monitor your Apache Spark applications. To monitor running Apache Spark application Open Monitor, then select Apache Spark applications. To view the details about the Apache Spark applications that are running, select the submitting Apache Spark application and view the details. If the Apache Spark application is still running, you can monitor the progress.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/monitoring/apache-spark-applications
You are designing database for an Azure Synapse Analytics dedicated SQL pool to support workloads for detecting ecommerce transaction fraud.
Data will be combined from multiple ecommerce sites and can include sensitive financial information such as credit card numbers.
You need to recommend a solution that meets the following requirements:
- Users must be able to identify potentially fraudulent transactions.
- Users must be able to use credit cards as a potential feature in models.
- Users must NOT be able to access the actual credit card numbers.
What should you include in the recommendation?
Transparent Data Encryption (TDE)
row-level security (RLS)
column-level encryption
Azure Active Directory (Azure AD) pass-through authentication
Answer is column-level encryption
Use Always Encrypted to secure the required columns. You can configure Always Encrypted for individual database columns containing your sensitive data.
Always Encrypted is a feature designed to protect sensitive data, such as credit card numbers or national identification numbers (for example, U.S. social security numbers), stored in Azure SQL Database or SQL Server databases.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/security/encryption/always-encrypted-database-engine
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DateKey, ProductKey, RegionKey.
There are 120 unique product keys and 65 unique region keys.

Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew.
What should you recommend?

1. Hash Distributed, ProductKey because >2GB and ProductKey is extensively used in joins
2. Hash Distributed, RegionKey because "The table size on disk is more than 2 GB." and you have to chose a distribution column which: "Is not used in WHERE clauses. This could narrow the query to not run on all the distributions."
Round-robin tables are useful for improving loading speed.
Consider using the round-robin distribution for your table in the following scenarios:
- When getting started as a simple starting point since it is the default
- If there is no obvious joining key
- If there is not good candidate column for hash distributing the table
- If the table does not share a common join key with other tables
- If the join is less significant than other joins in the query
- When the table is a temporary staging table
Note: A distributed table appears as a single table, but the rows are actually stored across 60 distributions. The rows are distributed with a hash or round-robin algorithm.
Reference:
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-tables-distribute
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute#choosing-a-distribution-column
You are designing a financial transactions table in an Azure Synapse Analytics dedicated SQL pool. The table will have a clustered columnstore index and will include the following columns:
- TransactionType: 40 million rows per transaction type
- CustomerSegment: 4 million per customer segment
- TransactionMonth: 65 million rows per month
- AccountType: 500 million per account type
You have the following query requirements:
- Analysts will most commonly analyze transactions for a given month.
- Transactions analysis will typically summarize transactions by transaction type, customer segment, and/or account type
You need to recommend a partition strategy for the table to minimize query times.
On which column should you recommend partitioning the table?
CustomerSegment
AccountType
TransactionType
TransactionMonth
Answer is TransactionMonth
the analyst will be querying transactions for month, and then its mentioned that transaction analysis will be done on Transaction_type, customer_segment and account_type, meaning they won't be querying for an individual columns but all 3 at the same time, which means it's pointless to partition between these columns, so transaction month is the answer.
In most cases data is partitioned on a date column that is closely tied to the order in which the data is loaded into the SQL pool.
Reference:
https://learn.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-partition?context=%2Fazure%2Fsynapse-analytics%2Fcontext%2Fcontext
https://learn.microsoft.com/en-us/azure/synapse-analytics/sql/best-practices-dedicated-sql-pool
Which of the following technologies typically provide an ingestion point for data streaming in an event processing solution that uses static data as a source?
IoT Hubs
Event Hubs
Azure Blob storage
Answer is Azure Blob storage
Azure Blob storage provide an ingestion point for data streaming in an event processing solution that uses static data as a source.
IoT hubs provide an ingestion point for data streaming in an event processing solution that uses streaming data from an IoT device as a source.
Event hubs provide an ingestion point for data streaming in an event processing solution that uses streaming data from an application as a source.