DP-203: Data Engineering on Microsoft Azure
Question 11
What is the recommended storage format to use with Spark?
JSON
XML
Apache Parquet
Answer is Apache Parquet
Apache Parquet. Apache Parquet is a highly optimized solution for data storage and is the recommended option for storage.
You plan to perform batch processing in Azure Databricks once daily.
Which type of Databricks cluster should you use?
job
interactive
High Concurrency
Answer is job
Scheduled batch workloads (data engineers running ETL jobs)
This scenario involves running batch job JARs and notebooks on a regular cadence through the Databricks platform.
The suggested best practice is to launch a new cluster for each run of critical jobs. This helps avoid any issues (failures, missing SLA, and so on) due to an existing workload (noisy neighbor) on a shared cluster.
Note: Azure Databricks has two types of clusters: interactive and automated. You use interactive clusters to analyze data collaboratively with interactive notebooks. You use automated clusters to run fast and robust automated jobs.
References:
https://docs.databricks.com/administration-guide/cloud-configurations/aws/cmbp.html#scenario-3-scheduled-batch-workloads-data-engineers-running-etl-jobs
You are a data engineer implementing a lambda architecture on Microsoft Azure. You use an open-source big data solution to collect, process, and maintain data. The analytical data store performs poorly.
You must implement a solution that meets the following requirements:
- Provide data warehousing
- Reduce ongoing management activities
- Deliver SQL query responses in less than one second
Which type of cluster should you create?
Interactive Query
Apache Hadoop
Apache HBase
Apache Spark
Answer is Apache Spark
Lambda Architecture with Azure:
Azure offers you a combination of following technologies to accelerate real-time big data analytics:
1. Azure Cosmos DB, a globally distributed and multi-model database service.
2. Apache Spark for Azure HDInsight, a processing framework that runs large-scale data analytics applications.
3. Azure Cosmos DB change feed, which streams new data to the batch layer for HDInsight to process.
4. The Spark to Azure Cosmos DB Connector
Note: Lambda architecture is a data-processing architecture designed to handle massive quantities of data by taking advantage of both batch processing and stream processing methods, and minimizing the latency involved in querying big data.
References:
https://sqlwithmanoj.com/2018/02/16/what-is-lambda-architecture-and-what-azure-offers-with-its-new-cosmos-db/
You plan to perform batch processing in Azure Databricks once daily.
Which type of Databricks cluster should you use?
automated
interactive
High Concurrency
Answer is automated
Azure Databricks has two types of clusters: interactive and automated. You use interactive clusters to analyze data collaboratively with interactive notebooks. You use automated clusters to run fast and robust automated jobs.
Example: Scheduled batch workloads (data engineers running ETL jobs)
This scenario involves running batch job JARs and notebooks on a regular cadence through the Databricks platform.
The suggested best practice is to launch a new cluster for each run of critical jobs. This helps avoid any issues (failures, missing SLA, and so on) due to an existing workload (noisy neighbor) on a shared cluster.
Reference:
https://docs.databricks.com/administration-guide/cloud-configurations/aws/cmbp.html#scenario-3-scheduled-batch-workloads-data-engineers-running-etl-jobs
Your company plans to create an event processing engine to handle streaming data from Twitter.
The data engineering team uses Azure Event Hubs to ingest the streaming data.
You need to implement a solution that uses Azure Databricks to receive the streaming data from the Azure Event Hubs.
Which three actions should you recommend be performed in sequence?
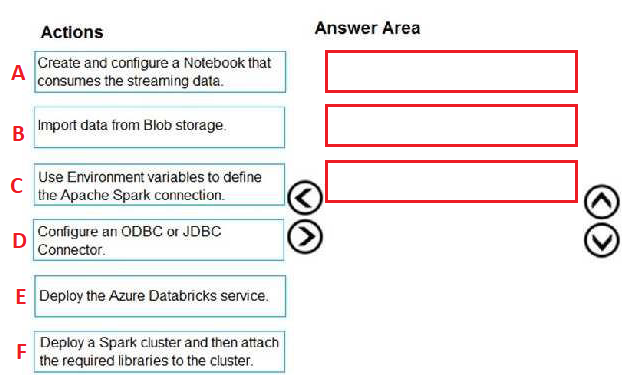
A-B-C
B-C-D
C-D-E
D-E-F
E-F-A
F-A-B
Answer is E-F-A

Step 1: Deploy the Azure Databricks service
Create an Azure Databricks workspace by setting up an Azure Databricks Service.
Step 2: Deploy a Spark cluster and then attach the required libraries to the cluster.
To create a Spark cluster in Databricks, in the Azure portal, go to the Databricks workspace that you created, and then select Launch Workspace.
Attach libraries to Spark cluster: you use the Twitter APIs to send tweets to Event Hubs. You also use the Apache Spark Event Hubs connector to read and write data into Azure Event Hubs. To use these APIs as part of your cluster, add them as libraries to Azure Databricks and associate them with your Spark cluster.
Step 3: Create and configure a Notebook that consumes the streaming data.
You create a notebook named ReadTweetsFromEventhub in Databricks workspace. ReadTweetsFromEventHub is a consumer notebook you use to read the tweets from Event Hubs.
References:
https://docs.microsoft.com/en-us/azure/azure-databricks/databricks-stream-from-eventhubs
You are developing a solution using a Lambda architecture on Microsoft Azure.
The data at rest layer must meet the following requirements:
Data storage:
- Serve as a repository for high volumes of large files in various formats.
- Implement optimized storage for big data analytics workloads.
- Ensure that data can be organized using a hierarchical structure.
Batch processing:
- Use a managed solution for in-memory computation processing.
- Natively support Scala, Python, and R programming languages.
Provide the ability to resize and terminate the cluster automatically.
Analytical data store:
- Support parallel processing.
- Use columnar storage.
- Support SQL-based languages.
You need to identify the correct technologies to build the Lambda architecture.
Which technologies should you use?
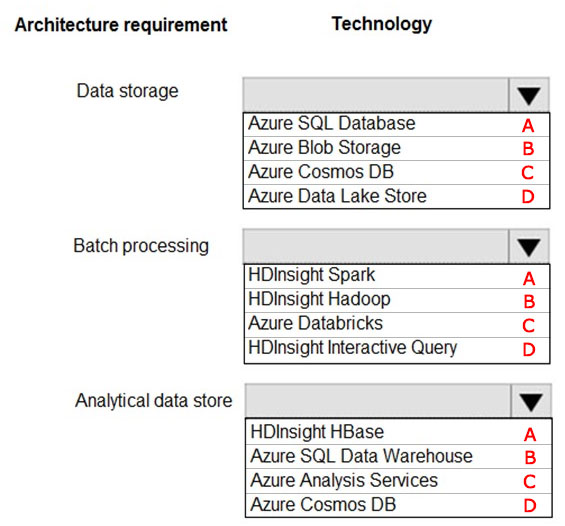
A-B-C
B-A-D
C-A-B
D-A-B
A-C-D
B-D-A
C-D-A
D-D-C
Answer is D-A-B
Data storage: Azure Data Lake Store
A key mechanism that allows Azure Data Lake Storage Gen2 to provide file system performance at object storage scale and prices is the addition of a hierarchical namespace. This allows the collection of objects/files within an account to be organized into a hierarchy of directories and nested subdirectories in the same way that the file system on your computer is organized. With the hierarchical namespace enabled, a storage account becomes capable of providing the scalability and cost-effectiveness of object storage, with file system semantics that are familiar to analytics engines and frameworks.
Batch processing: HD Insight Spark
Aparch Spark is an open-source, parallel-processing framework that supports in-memory processing to boost the performance of big-data analysis applications.
HDInsight is a managed Hadoop service. Use it deploy and manage Hadoop clusters in Azure. For batch processing, you can use Spark, Hive, Hive LLAP, MapReduce.
Languages: R, Python, Java, Scala, SQL
Analytic data store: SQL Data Warehouse
SQL Data Warehouse is a cloud-based Enterprise Data Warehouse (EDW) that uses Massively Parallel Processing (MPP).
SQL Data Warehouse stores data into relational tables with columnar storage.
References:
https://docs.microsoft.com/en-us/azure/storage/blobs/data-lake-storage-namespace
https://docs.microsoft.com/en-us/azure/architecture/data-guide/technology-choices/batch-processing
https://docs.microsoft.com/en-us/azure/sql-data-warehouse/sql-data-warehouse-overview-what-is
You need to collect application metrics, streaming query events, and application log messages for an Azure Databricks cluster.
Which type of library and workspace should you implement?
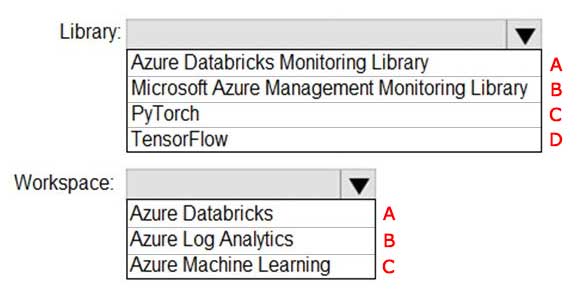
A-A
A-B
A-C
B-A
B-B
B-C
C-A
C-B
Answer is A-B
You can send application logs and metrics from Azure Databricks to a Log Analytics workspace. It uses the Azure Databricks Monitoring Library, which is available on GitHub.
References:
https://docs.microsoft.com/en-us/azure/architecture/databricks-monitoring/application-logs
You have an Azure Databricks resource.
You need to log actions that relate to compute changes triggered by the Databricks resources.
Which Databricks services should you log?
workspace
SSH
DBFS
clusters
jobs
Answer is clusters
An Azure Databricks cluster is a set of computation resources and configurations on which you run data engineering, data science, and data analytics workloads.
Incorrect Answers:
A: An Azure Databricks workspace is an environment for accessing all of your Azure Databricks assets. The workspace organizes objects (notebooks, libraries, and experiments) into folders, and provides access to data and computational resources such as clusters and jobs.
B: SSH allows you to log into Apache Spark clusters remotely.
C: Databricks File System (DBFS) is a distributed file system mounted into an Azure Databricks workspace and available on Azure Databricks clusters.
E: A job is a way of running a notebook or JAR either immediately or on a scheduled basis.
Reference:
https://docs.microsoft.com/en-us/azure/databricks/clusters/
Your company analyzes images from security cameras and sends alerts to security teams that respond to unusual activity. The solution uses Azure Databricks.
You need to send Apache Spark level events, Spark Structured Streaming metrics, and application metrics to Azure Monitor.
Which three actions should you perform in sequence?
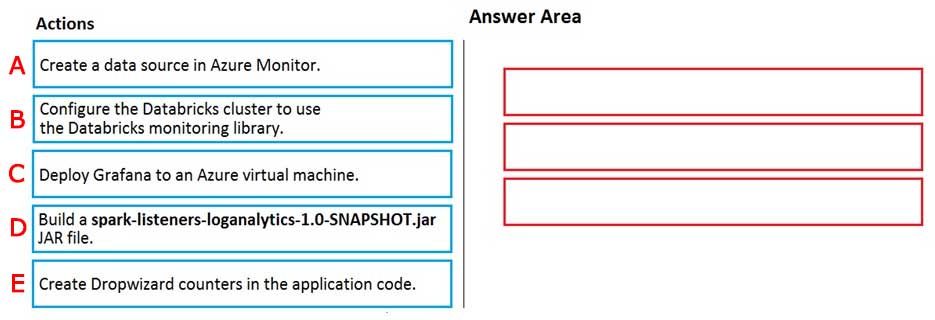
A-C-D
B-D-E
C-B-E
D-E-A
E-C-B
A-D-C
B-C-D
C-B-A
Answer is B-D-E
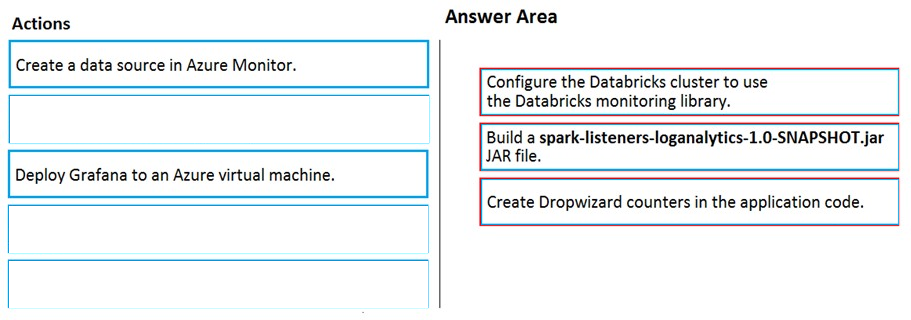
You can send application logs and metrics from Azure Databricks to a Log Analytics workspace.
Spark uses a configurable metrics system based on the Dropwizard Metrics Library.
Prerequisites: Configure your Azure Databricks cluster to use the monitoring library.
Note: The monitoring library streams Apache Spark level events and Spark Structured Streaming metrics from your jobs to Azure Monitor.
To send application metrics from Azure Databricks application code to Azure Monitor, follow these steps:
Step 1. Build the spark-listeners-loganalytics-1.0-SNAPSHOT.jar JAR file
Step 2: Create Dropwizard gauges or counters in your application code.
Reference:
https://docs.microsoft.com/bs-latn-ba/azure/architecture/databricks-monitoring/application-logs
You plan to build a structured streaming solution in Azure Databricks. The solution will count new events in five-minute intervals and report only events that arrive during the interval. The output will be sent to a Delta Lake table.
Which output mode should you use?
complete
update
append
Answer is append
Append Mode: Only new rows appended in the result table since the last trigger are written to external storage. This is applicable only for the queries where existing rows in the Result Table are not expected to change.
Incorrect Answers:
A: Complete Mode: The entire updated result table is written to external storage. It is up to the storage connector to decide how to handle the writing of the entire table.
B: Update Mode: Only the rows that were updated in the result table since the last trigger are written to external storage. This is different from Complete Mode in that Update Mode outputs only the rows that have changed since the last trigger. If the query doesn't contain aggregations, it is equivalent to Append mode.
Reference:
https://docs.databricks.com/getting-started/spark/streaming.html