DP-203: Data Engineering on Microsoft Azure
Question 131
You are designing a date dimension table in an Azure Synapse Analytics dedicated SQL pool. The date dimension table will be used by all the fact tables.
Which distribution type should you recommend to minimize data movement?
HASH
REPLICATE
ROUND_ROBIN
Answer is REPLICATE
A replicated table has a full copy of the table available on every Compute node. Queries run fast on replicated tables since joins on replicated tables don't require data movement. Replication requires extra storage, though, and isn't practical for large tables.
Incorrect Answers:
A: A hash distributed table is designed to achieve high performance for queries on large tables.
C: A round-robin table distributes table rows evenly across all distributions. The rows are distributed randomly. Loading data into a round-robin table is fast. Keep in mind that queries can require more data movement than the other distribution methods.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-overview
You are designing a security model for an Azure Synapse Analytics dedicated SQL pool that will support multiple companies.
You need to ensure that users from each company can view only the data of their respective company.
Which two objects should you include in the solution? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
a security policy
a custom role-based access control (RBAC) role
a function
a column encryption key
asymmetric keys
A: Row-Level Security (RLS) enables you to use group membership or execution context to control access to rows in a database table. Implement RLS by using the CREATE SECURITY POLICYTransact-SQL statement.
B: Azure Synapse provides a comprehensive and fine-grained access control system, that integrates:
Azure roles for resource management and access to data in storage,

● Synapse roles for managing live access to code and execution,
● SQL roles for data plane access to data in SQL pools.
Reference:
https://docs.microsoft.com/en-us/sql/relational-databases/security/row-level-security
https://docs.microsoft.com/en-us/azure/synapse-analytics/security/synapse-workspace-access-control-overview
You have a SQL pool in Azure Synapse that contains a table named dbo.Customers. The table contains a column name Email.
You need to prevent nonadministrative users from seeing the full email addresses in the Email column. The users must see values in a format of aXXX@XXXX.com instead.
What should you do?
From Microsoft SQL Server Management Studio, set an email mask on the Email column.
From the Azure portal, set a mask on the Email column.
From Microsoft SQL Server Management Studio, grant the SELECT permission to the users for all the columns in the dbo.Customers table except Email.
From the Azure portal, set a sensitivity classification of Confidential for the Email column.
Answer is From Microsoft SQL Server Management Studio, set an email mask on the Email column.
B can work but not by default.
The Email masking method, which exposes the first letter and replaces the domain with XXX.com using a constant string prefix in the form of an email address. aXX@XXXX.com
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
You have an Azure Data Lake Storage Gen2 account named adls2 that is protected by a virtual network.
You are designing a SQL pool in Azure Synapse that will use adls2 as a source.
What should you use to authenticate to adls2?
an Azure Active Directory (Azure AD) user
a shared key
a shared access signature (SAS)
a managed identity
Answer is a managed identity
Managed Identity authentication is required when your storage account is attached to a VNet.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/quickstart-bulk-load-copy-tsql-examples
You are designing an Azure Synapse solution that will provide a query interface for the data stored in an Azure Storage account. The storage account is only accessible from a virtual network.
You need to recommend an authentication mechanism to ensure that the solution can access the source data.
What should you recommend?
a managed identity
anonymous public read access
a shared key
Answer is a managed identity
Managed Identity authentication is required when your storage account is attached to a VNet.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/quickstart-bulk-load-copy-tsql-examples
You have an Azure Synapse Analytics dedicated SQL pool that contains a table named Contacts. Contacts contains a column named Phone.
You need to ensure that users in a specific role only see the last four digits of a phone number when querying the Phone column.
What should you include in the solution?
table partitions
a default value
row-level security (RLS)
column encryption
dynamic data masking
Answer is dynamic data masking
Dynamic data masking helps prevent unauthorized access to sensitive data by enabling customers to designate how much of the sensitive data to reveal with minimal impact on the application layer. It's a policy-based security feature that hides the sensitive data in the result set of a query over designated database fields, while the data in the database is not changed.
Reference:
https://docs.microsoft.com/en-us/azure/azure-sql/database/dynamic-data-masking-overview
You have an on-premises data warehouse that includes the following fact tables. Both tables have the following columns: DateKey, ProductKey, RegionKey. There are 120 unique product keys and 65 unique region keys.

Queries that use the data warehouse take a long time to complete.
You plan to migrate the solution to use Azure Synapse Analytics. You need to ensure that the Azure-based solution optimizes query performance and minimizes processing skew.
What should you recommend?
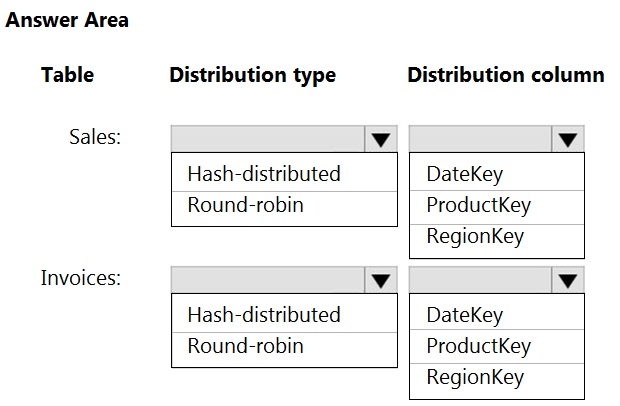
1. Hash Distributed, ProductKey
because >2GB and ProductKey is extensively used in joins
2. Hash Distributed, RegionKey
because "The table size on disk is more than 2 GB." and you have to chose a distribution column which: "Is not used in WHERE clauses. This could narrow the query to not run on all the distributions."
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-distribute#choosing-a-distribution-column
You have an Azure data solution that contains an enterprise data warehouse in Azure Synapse Analytics named DW1.
Several users execute ad hoc queries to DW1 concurrently.
You regularly perform automated data loads to DW1.
You need to ensure that the automated data loads have enough memory available to complete quickly and successfully when the adhoc queries run.
What should you do?
Hash distribute the large fact tables in DW1 before performing the automated data loads.
Assign a smaller resource class to the automated data load queries.
Assign a larger resource class to the automated data load queries.
Create sampled statistics for every column in each table of DW1.
Answer is Assign a larger resource class to the automated data load queries.
The performance capacity of a query is determined by the user's resource class. Resource classes are pre-determined resource limits in Synapse SQL pool that govern compute resources and concurrency for query execution.
Resource classes can help you configure resources for your queries by setting limits on the number of queries that run concurrently and on the compute-resources assigned to each query. There's a trade-off between memory and concurrency.
Smaller resource classes reduce the maximum memory per query, but increase concurrency.
Larger resource classes increase the maximum memory per query, but reduce concurrency.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/resource-classes-for-workload-management
You have an Azure Synapse Analytics dedicated SQL pool named Pool1 and a database named DB1. DB1 contains a fact table named Table1.
You need to identify the extent of the data skew in Table1.
What should you do in Synapse Studio?
Connect to the built-in pool and run DBCC PDW_SHOWSPACEUSED.
Connect to the built-in pool and run DBCC CHECKALLOC.
Connect to Pool1 and query sys.dm_pdw_node_status.
Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
Answer is Connect to Pool1 and query sys.dm_pdw_nodes_db_partition_stats.
Microsoft recommends use of sys.dm_pdw_nodes_db_partition_stats to analyze any skewness in the data.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/cheat-sheet
You are designing an inventory updates table in an Azure Synapse Analytics dedicated SQL pool. The table will have a clustered columnstore index and will include the following columns:

You identify the following usage patterns:
● Analysts will most commonly analyze transactions for a warehouse.
● Queries will summarize by product category type, date, and/or inventory event type.
You need to recommend a partition strategy for the table to minimize query times.
On which column should you partition the table?
EventTypeID
ProductCategoryTypeID
EventDate
WarehouseID
Answer is WarehouseID
The number of records for each warehouse is big enough for a good partitioning.
Note: Table partitions enable you to divide your data into smaller groups of data. In most cases, table partitions are created on a date column.
When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributed databases.
"When creating partitions on clustered columnstore tables, it is important to consider how many rows belong to each partition. For optimal compression and performance of clustered columnstore tables, a minimum of 1 million rows per distribution and partition is needed. Before partitions are created, dedicated SQL pool already divides each table into 60 distributed databases. Any partitioning added to a table is in addition to the distributions created behind the scenes. Using this example, if the sales fact table contained 36 monthly partitions, and given that a dedicated SQL pool has 60 distributions, then the sales fact table should contain 60 million rows per month, or 2.1 billion rows when all months are populated. If a table contains fewer than the recommended minimum number of rows per partition, consider using fewer partitions in order to increase the number of rows per partition."
It is recommended to have at least 1 million rows per partition and distribution. Since there are 60 distributions, the number of rows for each partition must exceed 60 millions.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/sql-data-warehouse/sql-data-warehouse-tables-partition