DP-203: Data Engineering on Microsoft Azure
Question 181
You are designing an Azure Stream Analytics job to process incoming events from sensors in retail environments.
You need to process the events to produce a running average of shopper counts during the previous 15 minutes, calculated at five-minute intervals.
Which type of window should you use?
snapshot
tumbling
hopping
sliding
Answer is hopping
As we need to calculate running average, which means it will have overlapping.
Reference:
https://docs.microsoft.com/en-us/stream-analytics-query/tumbling-window-azure-stream-analytics
You use Azure Stream Analytics to receive data from Azure Event Hubs and to output the data to an Azure Blob Storage account.
You need to output the count of records received from the last five minutes every minute.
Which windowing function should you use?
Session
Tumbling
Sliding
Hopping
Answer is Hopping
Hopping window functions hop forward in time by a fixed period. It may be easy to think of them as Tumbling windows that can overlap and be emitted more often than the window size. Events can belong to more than one Hopping window result set. To make a Hopping window the same as a Tumbling window, specify the hop size to be the same as the window size.

Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
You are designing a monitoring solution for a fleet of 500 vehicles. Each vehicle has a GPS tracking device that sends data to an Azure event hub once per minute.
You have a CSV file in an Azure Data Lake Storage Gen2 container. The file maintains the expected geographical area in which each vehicle should be.
You need to ensure that when a GPS position is outside the expected area, a message is added to another event hub for processing within 30 seconds. The solution must minimize cost.
What should you include in the solution?
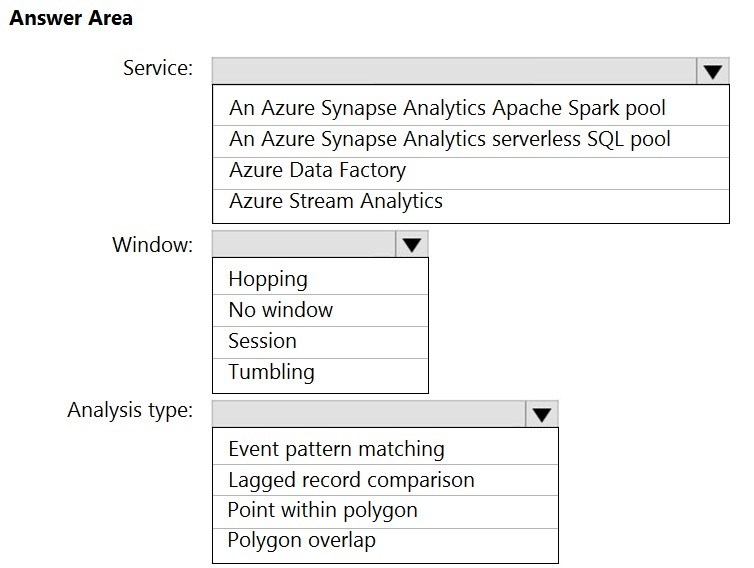
Box 1: Azure Stream Analytics
Box 2: No Window
Box 3: Point within polygon
No Window because you can write a query that joins the device stream with the geofence reference data and generates an alert every time a device is outside of an allowed building.
SELECT DeviceStreamInput.DeviceID, SiteReferenceInput.SiteID, SiteReferenceInput.SiteName
INTO Output
FROM DeviceStreamInput JOIN SiteReferenceInput ON st_within(DeviceStreamInput.GeoPosition, SiteReferenceInput.Geofence) = 0
WHERE DeviceStreamInput.DeviceID = SiteReferenceInput.AllowedDeviceID
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
https://docs.microsoft.com/en-us/azure/stream-analytics/geospatial-scenarios#generate-alerts-with-geofence
You are monitoring an Azure Stream Analytics job by using metrics in Azure.
You discover that during the last 12 hours, the average watermark delay is consistently greater than the configured late arrival tolerance.
What is a possible cause of this behavior?
Events whose application timestamp is earlier than their arrival time by more than five minutes arrive as inputs.
There are errors in the input data.
The late arrival policy causes events to be dropped.
The job lacks the resources to process the volume of incoming data.
Answer is The job lacks the resources to process the volume of incoming data.
Watermark Delay indicates the delay of the streaming data processing job.
There are a number of resource constraints that can cause the streaming pipeline to slow down. The watermark delay metric can rise due to:
1. Not enough processing resources in Stream Analytics to handle the volume of input events. To scale up resources, see Understand and adjust Streaming
Units.
2. Not enough throughput within the input event brokers, so they are throttled. For possible solutions, see Automatically scale up Azure Event Hubs throughput units.
3. Output sinks are not provisioned with enough capacity, so they are throttled. The possible solutions vary widely based on the flavor of output service being used.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-time-handling
You are building an Azure Stream Analytics job to retrieve game data.
You need to ensure that the job returns the highest scoring record for each five-minute time interval of each game.
How should you complete the Stream Analytics query?

Box 1: TopOne OVER(PARTITION BY Game ORDER BY Score Desc)
TopOne returns the top-rank record, where rank defines the ranking position of the event in the window according to the specified ordering. Ordering/ranking is based on event columns and can be specified in ORDER BY clause.
Box 2: Tumbling
Syntax for Hopping window requires 3 arguments, seems this should be Tumbling Window which fulfils the exact same requirements.
Reference:
https://docs.microsoft.com/en-us/stream-analytics-query/topone-azure-stream-analytics
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-window-functions
You are designing a streaming data solution that will ingest variable volumes of data.
You need to ensure that you can change the partition count after creation.
Which service should you use to ingest the data?
Azure Event Hubs Dedicated
Azure Stream Analytics
Azure Data Factory
Azure Synapse Analytics
Answer is Azure Event Hubs Dedicated
You can't change the partition count for an event hub after its creation except for the event hub in a dedicated cluster.
Reference:
https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-features
A company purchases IoT devices to monitor manufacturing machinery. The company uses an Azure IoT Hub to communicate with the IoT devices.
The company must be able to monitor the devices in real-time.
You need to design the solution.
What should you recommend?
Azure Data Factory instance using Azure Portal
Azure Data Factory instance using Azure PowerShell
Azure Stream Analytics cloud job using Azure Portal
Azure Data Factory instance using Microsoft Visual Studio
Answer is Azure Stream Analytics cloud job using Azure Portal
In a real-world scenario, you could have hundreds of these sensors generating events as a stream. Ideally, a gateway device would run code to push these events to Azure Event Hubs or Azure IoT Hubs. Your Stream Analytics job would ingest these events from Event Hubs and run real-time analytics queries against the streams.
Create a Stream Analytics job:
In the Azure portal, select + Create a resource from the left navigation menu. Then, select Stream Analytics job from Analytics.
Reference:
https://docs.microsoft.com/en-us/azure/stream-analytics/stream-analytics-get-started-with-azure-stream-analytics-to-process-data-from-iot-devices
You are designing an anomaly detection solution for streaming data from an Azure IoT hub. The solution must meet the following requirements:
- Send the output to Azure Synapse.
- Identify spikes and dips in time series data.
- Minimize development and configuration effort.
Which should you include in the solution?
Azure Databricks
Azure Stream Analytics
Azure SQL Database
Answer is Azure Stream Analytics
You can identify anomalies by routing data via IoT Hub to a built-in ML model in Azure Stream Analytics.
Reference:
https://docs.microsoft.com/en-us/learn/modules/data-anomaly-detection-using-azure-iot-hub/
You are a data engineer. You are designing a Hadoop Distributed File System (HDFS) architecture. You plan to use Microsoft Azure Data Lake as a data storage repository.
You must provision the repository with a resilient data schema. You need to ensure the resiliency of the Azure Data Lake Storage. What should you use?

A - A - A
A - A - B
A - B - B
B - A - A
B - A - B
B - B - A
B - B - B
Answer is B - A - A
Box 1: NameNode
An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients.
Box 2: DataNode
The DataNodes are responsible for serving read and write requests from the file system"™s clients.
Box 3: DataNode
The DataNodes perform block creation, deletion, and replication upon instruction from the NameNode.
Note: HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system's clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
References:
https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html#NameNode+and+DataNodes
You have an Azure Synapse workspace named MyWorkspace that contains an Apache Spark database named mytestdb.
You run the following command in an Azure Synapse Analytics Spark pool in MyWorkspace.
CREATE TABLE mytestdb.myParquetTable( EmployeeID int, EmployeeName string, EmployeeStartDate date) USING ParquetYou then use Spark to insert a row into mytestdb.myParquetTable. The row contains the following data.

One minute later, you execute the following query from a serverless SQL pool in MyWorkspace.
SELECT EmployeeID FROM mytestdb.dbo.myParquetTable WHERE name = 'Alice';What will be returned by the query?
24
an error
a null value
Answer is an error
Once a database has been created by a Spark job, you can create tables in it with Spark that use Parquet as the storage format. Table names will be converted to lower case and need to be queried using the lower case name. These tables will immediately become available for querying by any of the Azure Synapse workspace Spark pools. The Spark created, managed, and external tables are also made available as external tables with the same name in the corresponding synchronized database in serverless SQL pool.
Reference:
https://docs.microsoft.com/en-us/azure/synapse-analytics/metadata/table